前者の場合、端末でスクロールアウトするHTMLを見ながらXPathをこさえて間違ったらズラズラズラ…と画面が流れて行ってしまいます。後者の場合は、CLASSやID属性を使わないXPathが出来上がってしまいます。
映画に出てくるHackerの如く一発でXPathを決められればそれは素晴らしい事だと思いますが、いかんせん幾度か失敗しますよね。
で、何回もXPathを確かめられるツールが欲しいなと思い、perl-GTK2で作ってみました。
画面はこんな感じ
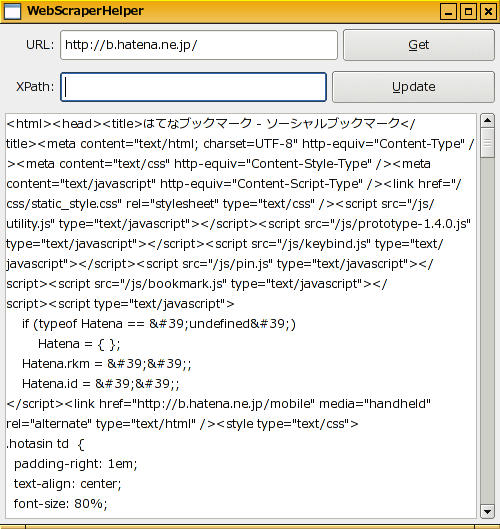
引数に「http://b.hatena.ne.jp/」を付けて起動したらこんな感じ
URLを変更して「Get」をクリックすれば再読み込みします。
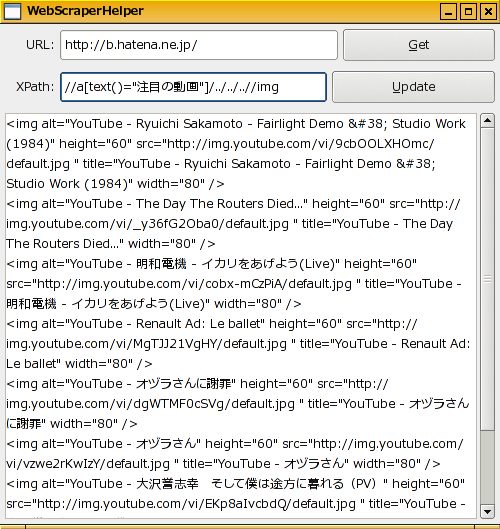
そして、はてなブックマークトップページの「注目の動画」部分にある画像一覧を取得する為に
//a[text()="注目の動画"]/../../..//img
というXPathを書いて「Update」をクリックすればこんな感じのHTMLが出来上がります。
あとはこれをWeb::Scraperのprocess部分に貼っつけるだけ。
ちなみにXPathでの属性値参照も出来ますので、はてなブックマークトップページで
//meta[@http-equiv="Content-Type"]/@content
というXPathを書けば
content="text/html; charset=UTF-8"
という結果が返ります。起動にはCPANからGtk2モジュールをインストールする必要があります。HTMLのパース方法やノードの取得方法等は大体Web::Scraperと合わせていますので、Web::Scraperが動く環境にGtk2をインストールすれば動くかと思います。
また画面はLinux上で起動した物ですが、UN*Xらしい事は一切やってませんのでWindowsでも動作するかと思います。
ダウンロード:
もう少し機能を足そうかと思いましたが、今日はもうギブアップ。寝ます。




